
In mijn vorige blog heb ik heel globaal aangegeven hoe de dataset van rechtspraak.nl eruit ziet. In deze dataset zitten ongeveer 2,2 miljoen uitspraken van de Nederlandse overheidsrechter. Per uitspraak is metadata geregistreerd, en van een deel van deze 2,2 miljoen uitspraken is ook de (al dan niet) integrale tekst opgenomen. Dat zijn er momenteel ongeveer 485.000.
Als wij naar de uitspraakteksten zelf kijken, dan beginnen we met wat de computer het beste kan: tellen. Omdat het om teksten gaat, beginnen we met het tellen van tekens, woorden en zinnen. Daar gaat echter wel een flinke preprocessing aan vooraf, want wat ziet de computer als een teken, woord of zin?
In de dataset van rechtspraak.nl is de uitspraaktekst opgenomen inclusief allerlei codes voor opmaak, bijvoorbeeld kopjes, citaten, tabellen, etc. Al die codes zijn ingesloten tussen twee vishaken (<>), dus makkelijk te verwijderen. Vervolgens is het aantal tekens goed te tellen. Voor het aantal woorden en zinnen heeft de computer iets meer instructie nodig, bijvoorbeeld in welke taal de uitspraak is geschreven, want wat in het Engels een woord is, is dat niet per sé ook in het Nederlands.
Woorden tellen
Laten wij de woorden eens tellen:
Gemiddeld heeft een uitspraken ongeveer 3.000 woorden. Maar er is een flink onderscheid in rechtsgebied. Een overzicht van de bell-curve:

Tellen van het aantal tekens en zinnen geeft vergelijkbare grafieken. Opvallend in bovenstaande grafiek is een aantal pieken aan de linkerkant: er zijn veel uitspraken met 250 woorden of minder. Dat zijn waarschijnlijk geen inhoudelijke oordelen, dus die verwijderen we voor deze blog uit de dataset.
Maar hoe verhoudt het aantal woorden als lengte van een uitspraak zich door de tijd heen? Met name civiele uitspraken worden de laatste jaren steeds langer, maar strafrechtelijke uitspraken zijn by far het langst en ook daar is sprake van een opgaande trend (maar let op de laatste ontwikkeling):

Zou die laatste ontwikkeling in strafuitspraken misschien met de invoering van het strafvonnis nieuwe stijl te maken hebben? Ik ben heel benieuwd hoe deze grafiek er over 6 maanden uit ziet.
Leesniveau
Een al in 1948 ontwikkelde methode om het leesniveau van een tekst te bepalen is de Flesch-methode. Deze methode berekent aan de hand van de gemiddelde lengte van een zin, het aantal lettergrepen en het aantal woorden wat het niveau van een taal is. Er zijn heel veel van dit soort methoden en er valt zeker veel aan te merken op deze formule, maar het geeft een indicatie en als je die indicator gebruikt voor een ontwikkeling door de tijd, dan denk ik dat het geoorloofd is om te stellen dat je een trend wel kunt herkennen (dames, heren statistici, ik verneem graag als ik het mis heb!). Ziehier het resultaat:
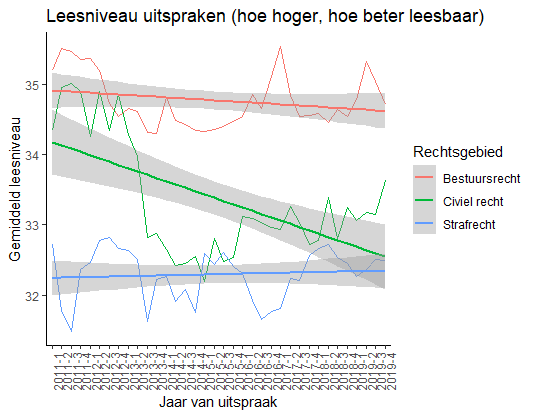
Wat is er gebeurd in 2012/2013 binnen het civiel recht dat de leesbaarheid van vonnissen zo enorm is gekelderd? Heb ik misschien toch de verkeerde methode gebruikt? Ik zou hier toch eens nader onderzoek naar moeten uitvoeren. Opvallend is ook dat de strafvonnissen moeilijker te lezen zijn dan vonnissen op het gebied van bestuursrecht. In dat opzicht is het niet gek dat strafvonnissen van een nieuwe stijl worden voorzien.
Ik ben niet bekend met een recent wetenschappelijk onderzoek naar het taalniveau van vonnissen, maar als iemand dat wel is, dan verneem ik dat natuurlijk graag.
Leesniveau bestuursrecht
Als we inzoomen op een aantal deelgebieden binnen het bestuursrecht, dan is het leesniveau van de deelrechtsgebieden als volgt:

Opvallend is dat het sociale zekerheidsrecht (totaal bijna 28.000 uitspraken) onbetwist de makkelijkst leesbare uitspraken produceert en dat in het bestuurlijke omgevingsrecht de leesbaarheid van uitspraken niet de prioriteit geniet.
Vragen?
Heb je vragen of opmerkingen? Ik ben heel benieuwd wat jullie vinden van deze blog. Laat je vragen hieronder achter of stuur me een e-mail!
Volgende blog
In mijn volgende blog zal ik schrijven over verwijzingen in uitspraken naar andere uitspraken. Wat zegt het over een uitspraak als andere uitspraken daarnaar verwijzen?